Runs on your own GPU · or in the cloud
Videos you can
search.
Drop in a video. Seconds later it's searchable, clickable and readable — every moment, every object, every word.
One workspace.
Three superpowers.
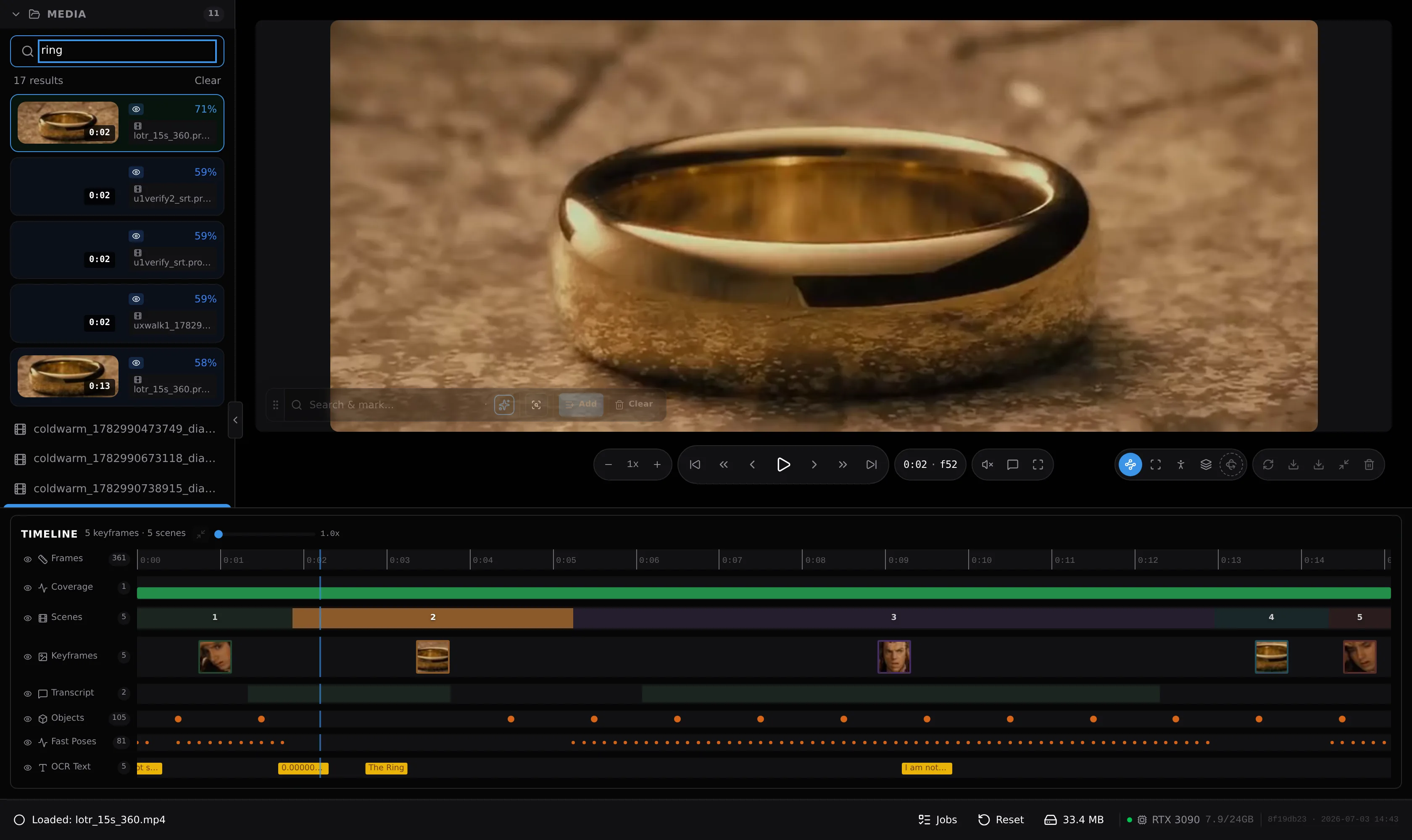
Type a word.
Jump to the moment.
Every frame is visually indexed, every spoken word transcribed. One search box covers both — type “car” and land on every car that appears or is mentioned.
- Visual search over every frame
- Transcript search, word-timed
- Results in ~40 ms per query
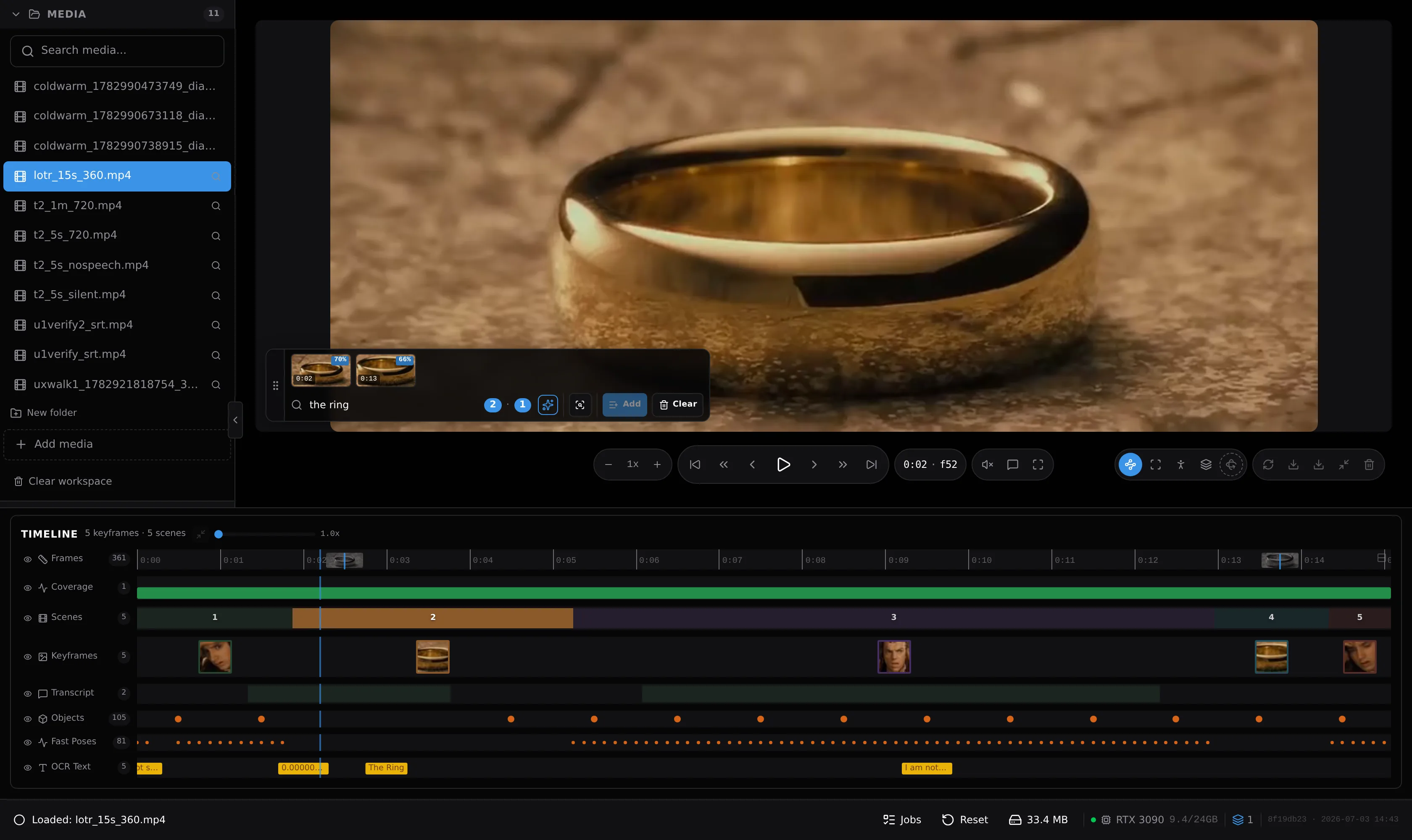
Click it.
It knows what it is.
Click anything in the frame — or draw a box. You get a pixel-perfect mask, an automatic name, and tracking through the clip.
- Segmentation on a single click
- Auto-labeling names the selection
- Track it across the whole video
The video writes
its own story.
Scene by scene, in plain language — with corrected dialogue rendered as quotes. Read any scene on its own, or export the whole thing as SRT.
- Scene-by-scene narrative
- Dialogue corrected, never invented
- One-click SRT export
A young man with intense, wide eyes presses a hand to his forehead in a close-up, appearing distressed.
— “Only there can it be unmade.” (off-screen voice)
A single gleaming gold ring rests on a textured, earthy surface, its polished surface reflecting the light.
A close-up shows a stern figure with pointed ears and a metallic headband, brows furrowed against a dim, earthy background.
— “It must be taken deep into Mordor and cast back into the fiery chasm from whence it came.” (the stern figure)
The same gold ring again — polished interior catching the light, the outer edge showing subtle wear.
Upload → searchable
in seconds
Scenes, keyframes, embeddings and transcript — indexed automatically on drop.
One click →
mask + name + track
Interactive segmentation with automatic labeling, ready to follow through the clip.
SRT out,
dialogue corrected
Mis-heard words fixed against what's on screen — never paraphrased, never invented.
UNDER THE HOOD